Beyond the Buzzwords: What a REAL RAG System Looks Like Under the Hood
Subtitle: It’s more than a library card. It’s about building a genius librarian.
The Untrained Genius in Your Office
You’ve seen what tools like ChatGPT can do. They are brilliant, but they are also fundamentally ignorant of your business. Ask one about your Q3 sales trends or your internal onboarding process, and it will politely decline. It’s like hiring a genius who has never read a single one of your company’s documents.
The common solution you hear about is Retrieval-Augmented Generation, or RAG. Most articles describe it with a simple analogy: “It’s like giving your AI a library card to your company’s data.” While true, this is a massive oversimplification. It’s the equivalent of saying a car is “a box with wheels.” It misses the engine, the transmission, and the engineering that makes it work.
Giving an AI a library card is easy. The real challenge—and where true expertise lies—is building a genius librarian that knows how to read, understand, and find the perfect piece of information in that library. This guide will take you under the hood to show you the engineering that separates a basic RAG system from a high-performing one that can transform your business.
Part 1: The Secret Language of AI - From Words to Vectors
First, we have to solve a fundamental problem: AI models don’t understand words. They are mathematical constructs that understand numbers. So, how does our Digital Librarian read your documents? It uses a special translator called an embedding model.
This model’s job is to convert every piece of your text—a sentence, a paragraph, a page—into a list of numbers called a vector. This isn’t just a random string of digits. It’s a rich, mathematical representation of the text’s meaning. For instance, the powerful models we use convert a single chunk of text into a vector of over 1,500 numbers.
Think of this vector as a precise coordinate on a giant, multi-dimensional “map of meaning.” On this map, concepts with similar meanings are located close to each other. The vector for “How do I reset my password?” will be a close neighbor to the vector for “I forgot my login credentials,” but very far from the vector for “What’s for lunch in the cafeteria?”
This is the first layer of expertise: choosing the right embedding model to create a rich, accurate meaning map. A bad map leads to a lost librarian.
Part 2: The Art of Building the Library - Why “Chunking” is a Superpower
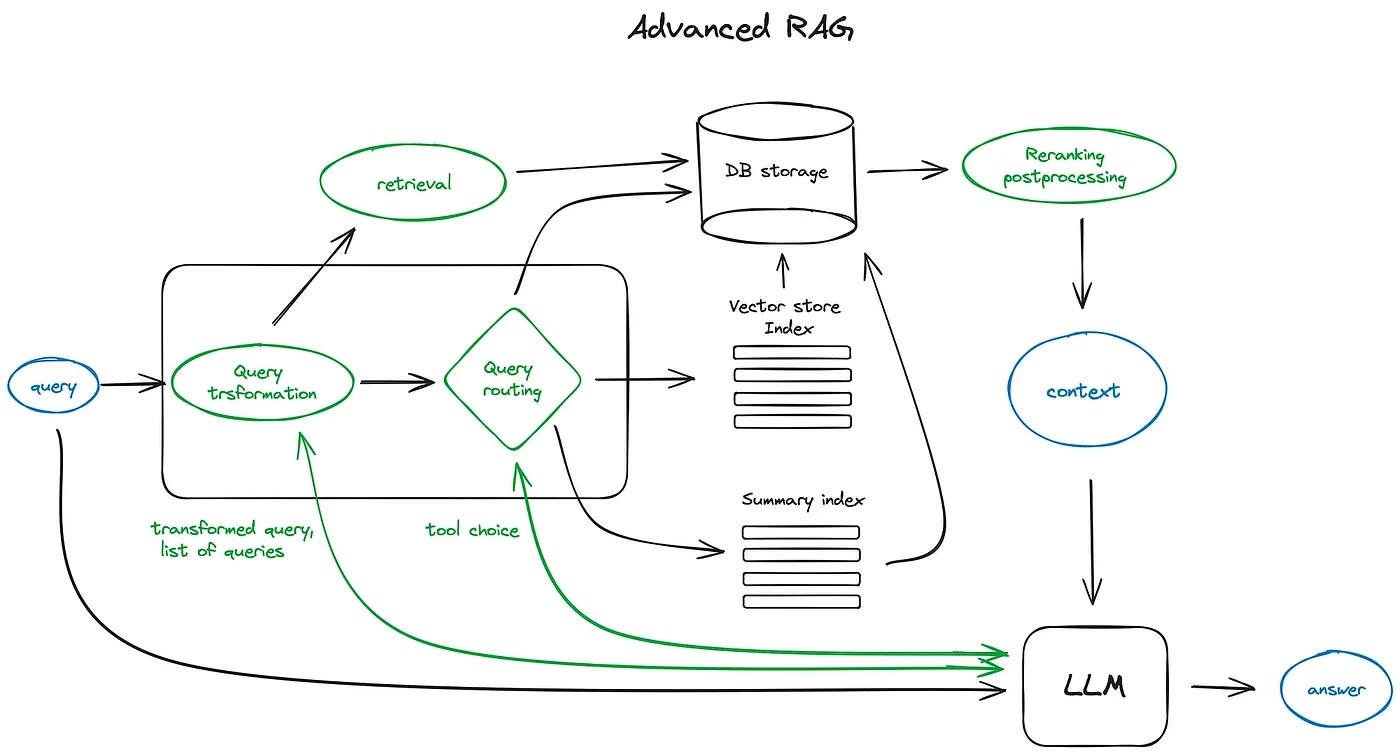
Now that we can translate documents into coordinates on our meaning map, how do we organize the library itself? You can’t just feed entire documents into the system. They must be broken down into smaller, meaningful chunks. This process, known as chunking, is arguably the most critical step in building a successful RAG system.
This is where the “art and alchemy” of RAG truly begins. The strategy you use for chunking has a massive impact on the quality of the answers you get. Consider the questions:
- Should a chunk be a single sentence or a whole paragraph?
- Should chunks overlap to ensure no context is lost at the edges?
- Should a table be treated as a single chunk, or should each row be its own?
A poor chunking strategy is like having a librarian who, when asked for a specific fact, hands you the entire 500-page book it came from. The AI will be overwhelmed with irrelevant information and will likely give a vague or incorrect answer. A sophisticated chunking strategy, however, ensures the librarian delivers the exact, concise paragraph needed. This is a core differentiator between a DIY system and an enterprise-grade solution.
Part 3: How the Librarian Finds the Perfect Page - The Magic of Similarity Search
So, your library is built. Every chunk of your documentation has been converted into a vector and placed as a coordinate on your meaning map. Now, a user asks a question. How does the librarian find the perfect page?
First, the user’s question is also converted into a vector using the same embedding model. It now has its own coordinate on the map. The system then uses a mathematical method—most often Cosine Similarity—to find the document chunks whose coordinates are closest to the question’s coordinate.
Think of it as the librarian’s GPS for navigating the meaning map. Cosine Similarity measures the “angle” between the question vector and all the document chunk vectors. A smaller angle means the concepts are more closely aligned. The system grabs the top few chunks with the smallest angles—the “nearest neighbors” on the map—and prepares them for the final step.
This is what makes RAG so powerful. It’s not matching keywords; it’s matching meaning. That’s how it knows that “employee benefits information” is related to “what is our dental plan?” even if the words are different.
Part 4: Beyond the Recipe - The “Alchemy” of World-Class RAG
We’ve now indexed the data into vectors, chunked it strategically, and used cosine similarity to find the most relevant information. The final step is to hand that information, along with the original question, to the Large Language Model (LLM) to generate a human-readable answer.
While the process sounds like a straightforward recipe, achieving excellence is an art. As our CTO, Ivan Sivak, often says, “A good RAG system is a little bit of alchemy.” Choosing the right embedding model for your specific type of data, designing a sophisticated chunking strategy, and tuning the retrieval algorithm are all variables that determine success. This is what separates a system that works “sometimes” from one that is reliably accurate and trustworthy.
Your Business, Powered by True Expertise
Understanding these components—vectors, chunking, and similarity search—is the first step toward appreciating what a truly effective RAG system entails. It’s far more than a simple library card; it’s a custom-built, genius-level librarian designed specifically for your business.
When you’re ready to move beyond the buzzwords and build an AI solution that can genuinely understand and interact with your company’s knowledge, it’s crucial to partner with experts who have mastered the alchemy. Ready to build your genius librarian? Let’s talk.