What Is RAG and Why Does It Matter for MSPs?
RAG lets AI models pull answers from your clients’ private documents instead of relying on generic training data. For MSPs, a production-grade RAG pipeline is the difference between deploying AI that guesses and AI that knows. The engineering behind embeddings, chunking, and similarity search determines whether a RAG system is reliable or unreliable.
Every week, at least one MSP partner asks us the same question: how does the AI know my client’s data? They have tried ChatGPT. They have pointed it at folders of SOPs. And the answers came back confident, plausible, and wrong.
Retrieval-Augmented Generation (RAG) connects a large language model to an external knowledge base so it retrieves verified, client-specific information before generating a response. According to a 2024 Pinecone analysis, the quality of the retrieval pipeline is the single largest determinant of answer accuracy in RAG systems. For MSPs, RAG is what separates AI that is useful for actual client work from AI that guesses.
Here is what every MSP needs to understand about RAG before deploying it: how the pipeline works, where it breaks, and what separates a demo from a production system your clients can rely on.
Why Do Generic AI Models Fail MSP Clients?
Large language models like ChatGPT train on public internet data. They have no access to your clients’ internal documents, SOPs, ticketing history, or proprietary knowledge bases. Ask one about a specific client’s Q3 revenue trend or their internal onboarding process and it will either decline or hallucinate an answer.
MSPs hit this wall the moment they deploy generic AI tools for clients. The model is capable, but it is uninformed. According to a 2025 Lansweeper survey, only 25% of MSPs have AI-driven service platforms ready to deploy as client offerings. The obstacle is not model quality. Most available tools cannot connect to the private data that makes AI useful in a business context.
Retrieval-Augmented Generation solves this by giving the AI model a structured pipeline to retrieve verified information from your client’s own data before generating a response. The model stops guessing and starts referencing.
How Do Embedding Models Turn Documents into Searchable Data?
AI models process numbers, not words. Before a RAG system can search your client’s documents, it converts text into a numerical format that captures meaning. An embedding model does this work.
An embedding model converts each piece of text, whether a sentence, paragraph, or page, into a list of numbers called a vector. This vector is a mathematical representation of the text’s meaning. Modern embedding models like the ones we use at Synthreo produce vectors with over 1,500 dimensions, creating a detailed map where similar concepts cluster together.
On that map, “How do I reset my password?” sits close to “I forgot my login credentials” but far from “What is the cafeteria menu?” According to a 2024 analysis published by Pinecone, the quality of the embedding model is the single largest determinant of retrieval accuracy in RAG systems. A poor embedding model creates a distorted map, meaning the system retrieves the wrong documents and produces wrong answers.
For MSPs deploying AI across client environments, this matters because different clients have different data types. Legal documents require different semantic understanding than IT ticketing data. The embedding model must match the domain.
Why Does Document Chunking Determine RAG Quality?
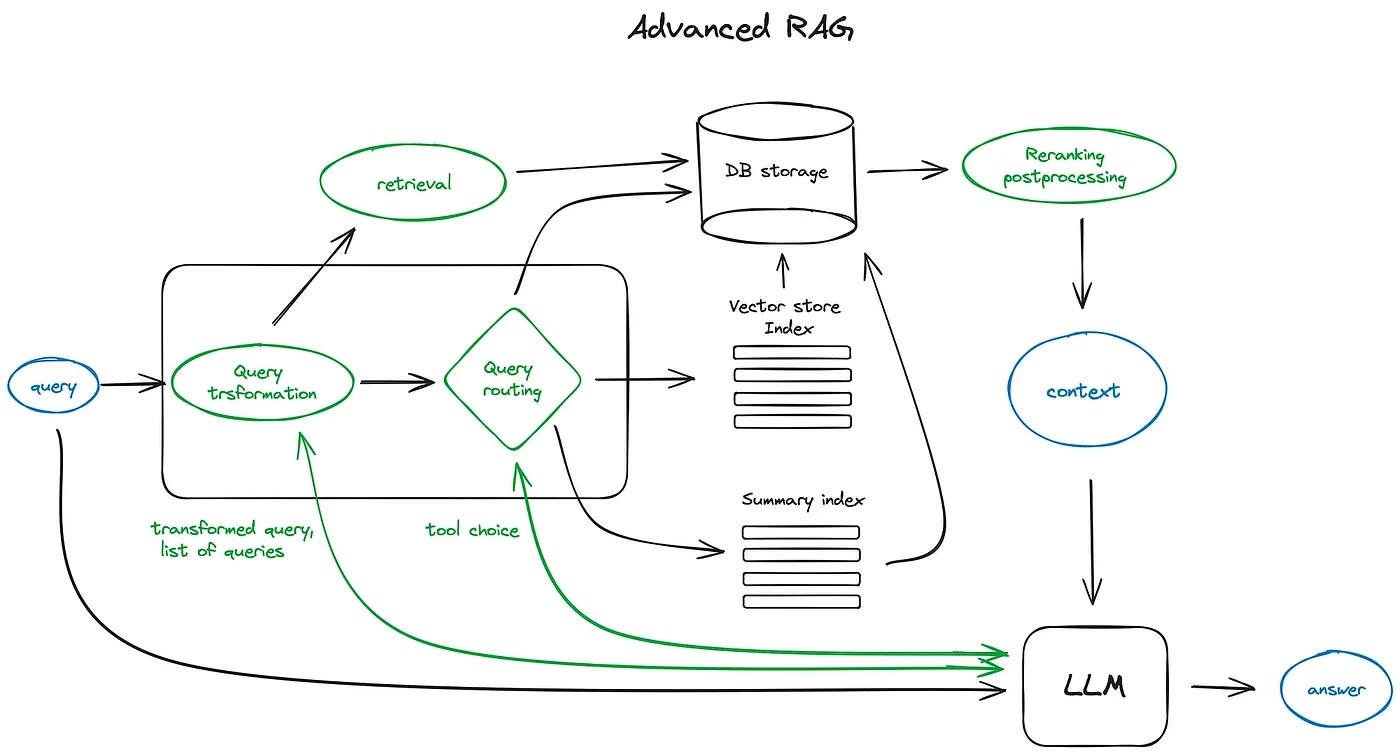
Once documents convert into vectors, the system must organize them for retrieval. You cannot feed entire 50-page documents into an AI model. You break them into smaller, meaningful pieces called chunks. This process, known as chunking, is the most consequential engineering decision in any RAG deployment.
Chunking strategy directly determines answer quality. If chunks are too large, the AI receives too much irrelevant context alongside the relevant passage and produces vague answers. If chunks are too small, the AI loses surrounding context needed to interpret the information correctly and produces incomplete answers.
Effective chunking also requires decisions about overlap. Should adjacent chunks share a few sentences at the boundaries so context is not lost at the edges? Should tables become single chunks or break into rows? Should headers attach to the paragraphs beneath them? These are not academic questions. We work through these tradeoffs on every client deployment because the answer changes based on the data.
According to LangChain’s RAG optimization documentation, poorly chunked data is the most common cause of low-quality RAG outputs in production deployments. Synthreo’s secure RAG pipeline handles chunking at the platform level, so MSPs do not need to make these engineering decisions for every client.
How Does Similarity Search Find the Right Information?
With documents chunked and embedded, the system is ready to answer questions. When a user submits a query, the RAG system converts that question into a vector using the same embedding model. It then searches the vector database for the document chunks whose vectors are closest to the question’s vector.
The most common method for this search is cosine similarity. It measures the angle between the question vector and each document chunk vector. A smaller angle means the concepts are more closely aligned. The system retrieves the top chunks with the smallest angles and passes them to the language model as context for generating the answer.
RAG differs from keyword search because it matches meaning rather than words. A query about “employee dental coverage” will retrieve a chunk about “benefits plan details” even if the word “dental” never appears in that chunk. According to Google Research, semantic search via embeddings outperforms keyword-based retrieval by 30-50% on information retrieval benchmarks, depending on the dataset and domain.
For MSPs managing multiple client environments, the quality of similarity search determines whether the AI returns the right answer from the right client’s data, not a document from a different tenant’s knowledge base. Tenant-level data isolation in the vector database is non-negotiable for any MSP-grade RAG deployment.
What Separates a Production-Grade RAG System from a Basic One?
Every RAG system uses the same steps: embedding, chunking, retrieval, and generation. Engineering quality at each step determines whether the system works reliably or fails unpredictably.
A basic RAG system uses default chunking sizes, a single general-purpose embedding model, and minimal tuning. It works in demos. It breaks in production when the data gets messy, the questions get complex, or the document formats vary across clients.
A production-grade RAG system tunes each variable to the specific data and use case. The embedding model matches the domain. The chunking strategy adapts to document types. The retrieval algorithm balances precision and recall. The entire pipeline runs within a multi-tenant architecture that keeps each client’s data isolated.
Our CTO, Ivan Sivak, puts it this way: “A good RAG system is a little bit of alchemy.” Choosing the right embedding model, designing the chunking strategy, and tuning retrieval separate a system that works sometimes from one that is reliably accurate.
The difference shows up in results. Arlin Sorensen, a 40-year MSP industry veteran and Synthreo advisory board member, used our RAG pipeline to index and unlock his entire 57,000-document leadership archive. Previous AI tools had failed to handle the volume and format diversity. Our pipeline transformed it into a conversational AI assistant that could surface insights from decades of content in seconds.
How Do MSPs Deploy RAG for Their Clients with Synthreo?
MSPs do not need to build RAG pipelines from scratch. We built a fully managed, secure RAG infrastructure purpose-built for multi-tenant MSP deployments. Synthreo handles the embedding, chunking, vector storage, retrieval, and generation layers so MSPs focus on identifying high-value client use cases and delivering outcomes.
ThreoAI, Synthreo’s secure AI chat product, gives clients a familiar, branded interface to interact with their RAG-powered AI agents. Builder, Synthreo’s no-code agent creation tool, lets MSPs configure knowledge bases, set behaviors, and deploy agents to client tenants without writing code. Every deployment runs within isolated tenant environments with zero data retention by default.
Most MSPs go live with their first client deployment within two to three weeks. No AI engineering team required. No per-token usage fees. A flat monthly subscription that makes revenue predictable for both the MSP and the client.
We built this pipeline so MSPs do not have to. If you want to see how RAG works in a live client environment, book a demo and we will walk you through it.
Frequently Asked Questions About RAG for MSPs
Q: What is Retrieval-Augmented Generation (RAG)?
A: RAG connects a large language model to an external knowledge base so it retrieves verified, business-specific information before generating a response. Instead of relying on generic training data, the AI references your actual documents, SOPs, and internal data to produce accurate answers.
Q: Why do MSPs need RAG instead of just using ChatGPT?
A: ChatGPT has no access to your clients’ private data. It cannot answer questions about internal processes, client-specific policies, or proprietary knowledge bases. RAG gives the AI model a structured pipeline to retrieve that private data securely, making responses relevant and accurate for each client environment.
Q: What is document chunking and why does it matter?
A: Chunking breaks documents into smaller, meaningful pieces before they are indexed for AI retrieval. The size and strategy of chunks directly determines answer quality. Chunks that are too large produce vague responses. Chunks that are too small lose context. Production-grade RAG systems tune chunking to the specific document types and use cases.
Q: Is RAG secure enough for MSP client data?
A: It depends on the platform. A production-grade RAG deployment requires tenant-level data isolation, zero data retention policies, and role-based access controls. Synthreo’s RAG pipeline enforces all three by default, with SOC 2, HIPAA, and GDPR alignment built into the infrastructure.
Q: How long does it take for an MSP to deploy RAG for a client?
A: With a purpose-built platform like Synthreo, most MSPs go live with their first client deployment within two to three weeks. The platform handles embedding, chunking, vector storage, and retrieval so MSPs do not need to build or maintain the pipeline themselves.
Q: What is the difference between basic RAG and production-grade RAG?
A: Basic RAG uses default settings for chunking, embedding, and retrieval. It works in demos but breaks in production when data gets messy or questions get complex. Production-grade RAG tunes each variable to the domain, adapts to document types, and runs within secure multi-tenant architecture with per-client data isolation.